Table of Contents¶
Chapter 1. 인공지능의 과거, 현재, 미래¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
01 인공지능이란¶
튜링 테스트 : 튜링 테스트란 기계인지 사람인지를 판별하는 시험으로 사람인 판정자가 상대방을 모르는 상태에서 질문과 답변에 응하여 사람인지 기계인지를 판별하는 방식으로 인공지능의 수준을 판별하는 방법입니다. 책에서는 판정자를 여러명 두어 판정자 중 30% 이상이 사람으로 생각해야 한다고 설명하고 있습니다. 주의할 점은 저자는 튜링 테스트가 지능을 측정하는 것이 아님을 명확히 밝히고 있습니다. 창의력을 요구하는 것 과 같은 것은 튜링 테스트 대상이 될 수 없다고 합니다.
03 인공지능의 발전 흐름¶
책에서는 다음과 같이 시기를 나누고 있습니다.
- 1960~1980년: 전문가 시스템 과 1차 인공지능 붐
- 1980~2000년: 2차 인공지능 붐과 신경망의 암흑기
- 이 당시에는
XOR문제를 해결하지 못하고 있다가 다층구조에 퍼셉트론을 사용하여 이 문제를 해결하여 붐이 이루어졌으나 컴퓨터 연상 성능의 발전이 따라오지 못하여 결국 산고범위 문제를 해결 할 수 없는 한계점에 다다르게 되어 90년대의 암흑기를 맞이하게 되었다고 설명하고 있습니다.
- 이 당시에는
- 2000~2010년: 통계 기반 머신러닝과 분산 처리 기술의 발전
- 이 시기에는 베이즈 정리와 분산 처리 기술이 발전하면서
Deep Neural Network로까지 연결되게 되었습니다.
- 이 시기에는 베이즈 정리와 분산 처리 기술이 발전하면서
- 2010년 이후: 심층 신경망 기반 이미지 인식 성능 향상과 3차 인공지능 붐
- 현재 우리가 살고 있는 상황입니다. 알파고를 필두로 하여 의료영역에서, 무인자동차에서, 번역기에서 활발한 적용이 시작되는 상황입니다.
Chapter 2. 규칙 기반 모델의 발전¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
01 규칙 기반 모델¶
- 규칙 기반 시스템
- 규칙(조건 설정)을 사용해 조건 분기 프로그램을 실행하는 시스템
- 프로그램이나 알고리즘의 순서도에서 사용하는 IF-THEN 형태로 표현하는 경우가 많습니다.
- 규칙 설계와 문제의 공식화
- 규칙을 설정할 때는 순서와 우선순위에 주의를 기울여야 합니다.
- 규칙을 설계해 나가는 단계에서 문제와 해법을 명확히 하는 것을 ‘문제의 공식화’라고 합니다.
- 의사 결정 트리의 구축
- 규칙을 바탕으로 그린 순서도로 구축한 이진 트리를 의사 결정 트리 (decision tree) 라고 합니다.
- 통계학에 기반을 두고 데이터를 처리하거나 분석할 때 자주 사용합니다.
02 지식 기반 모델¶
- 지식 기반 (knowledge base)
- 여러 번 다시 프로그래밍하는 불편함을 줄이고자 조건을 설졍하는 데이터 세트와 실제 데이터 세트를 처리하거나 출력하는 프로그램을 분리했습니다. 여기서 분리된 데이터 세트를 지식 기반이라고 합니다.
- 데이터를 처리하거나 출력하는 프로그램은 조건 분기가 필요할 때 지식 기반에 있는 (특정 규칙이 있는) ID를 사용해 설정값을 읽고 어떤 판단을 내립니다.
- UniProtKB: 유럽의 생명 과학 분야 기관들이 협력해 만든 지식 기반 데이터베이스 시스템
03 전문가 시스템¶
- 초기 전문가 시스템 Dendral
- 1965년 스탠퍼드 대학에서 시작된 프로젝트
- 어떤 물질의 질량을 분석하면서 피크(peak) 값(분자량)을 얻은 후 이를 해당 물질의 화학 구조를 파악할 때 이용합니다.
- 프로그램 언어: LISP
- MYCIN
- Dendral에서 파생해 발전한 전문가 시스템
- 환자의 전염성 혈액 질환을 진단한 후 투약해야하는 항생제, 투약량 등을 제시합니다.
- 추론 엔진
- 전문가 시스템이 규칙을 사용해 결과를 추론하는 프로그램
- 컴퓨터에서 규칙을 해석해 처리할 때 ‘수리논리학’을 이용합니다.
- 가장 기본적으로 사용하는 수리논리학 체계는 명제 논리 (propositional logic) 입니다.
- 명제 논리는 명제 변수와 논리 연산자를 이용해 논리식을 구성합니다.
04 추천 엔진¶
쇼핑몰 등의 사이트 방문자에게 비슷한 정보를 추천하는 시스템
- 콘텐츠 내용을 분석하는 추천 엔진
- 방문자 정보를 제외한 콘텐츠 자체의 정보에서 관련 있는 내용을 찾아 추천합니다.
- 협업 필터링을 이용하는 추천 엔진
- 검색 이력과 구매 이력 등 사이트 방문자의 고유 데이터를 이용해 방문자에게 적합한 무언가를 추천할 때는 협업 필터링이라는 알고리즘을 사용합니다.
Chapter 3. 오토마톤과 인공 생명 프로그램¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것입니다.
| Authors: | Woong Jeong |
|---|
01 인공 생명 시뮬레이션¶
인공 생명이란?¶
라이프 게임¶
감염 시뮬레이션¶
02 유한 오토마톤¶
오토마톤¶
오토마톤과 언어 이론¶
03 마르코프 모델¶
마르코프 모델의 주요 개념¶
마르코프 모델의 예¶
04 상태 기반 에이전트¶
게임 AI¶
에이전트¶
보드게임¶
보드게임의 게임 이론¶
복잡하게 구성된 에이전트 사용¶
Footnotes
| [1] | 생물과 무생물을 구별하는 가장 핵심적인 특징은 [ 자기증식능력 / 에너지변환능력 / 항상성유지능력 ]을 가지고 있어야 합니다. 위키피디아:생물 |
| [2] | 위키피디아:라이프게임 |
| [3] | 라이프 게임 테스트 |
| [4] | 질병관리본부:SIR모델 |
| [5] | 위키피디아:유한상태기계 |
| [6] | 위키피디아:형식언어 |
| [7] | 위키피디아:지능형에이전트 |
| [8] | CAIT:구동형에이전트 |
| [9] | 위키피디아:오델로(리버시) |
| [10] | 위키피디아:죄수의딜레마 |
| [11] | ``_ |
| [12] | ``_ |
Chapter 4. 가중치와 최적해 탐색¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
01 선형 문제와 비선형 문제¶
두 변수의 상관관계¶
선형 계획법¶
비선형 계획법¶
- 볼록 최적화(Convex Optimization) : 볼록 함수와 오목 함수로 점의 분포를 나타낼 수 있는 볼록 계획 문제를 해결하는 방법
- 분기 한정법(BB : branch and bound) : 볼록 함수가 아닐 때 선형 계획 문제와 볼록 계획 문제를 조합하여 해결하는 방법
02 회귀분석¶
회귀분석¶
회귀분석 : 주어진 데이터로 어떤 함수를 만들어 낸 후, 이 함수를 피팅하는 작업. 피팅은 함수에서 발생하는 차이(잔차의 크기)가 최소화되도록 함수를 조정해주는 것을 의미.
단순회귀¶
- 요소들 사이의 비례 관계를 활용하는 가장 기본적인 회귀분석 방법.
- 회귀직선의 기울기와 절편 구하기
- y=a +bx+e 에서 기울기와 절편을 알면 임의의 x에 대한 결괏값 y를 얻을 수 있음.
- y : 종속 변수 (목적 변수), x : 종속 변수 (설명 변수), e : 오차항
- 단순 회귀 모델 식을 기반으로 잔차의 제곱인 E를 구하는 식 도출.
- E : 목적 함수
- a, b 각각의 편미분을 이용해 연립 방정식을 만들어서 잔차의 제곱인 E가 최소화되는 값을 구함.
- 연립 편미분 방정식을 풀면 a, b 각각을 구하는 식으로 변환 가능.
다중회귀¶
- 독립 변수가 한 개인 단순회귀와 달리, 여러 개일 때 사용하는 회귀분석 방법. y=a+bx1+rx2+e (x1, x2는 독립 변수)
- 독립 변수가 늘 때의 단점
- 다중공선성(Multicollinearity) 문제 : 독립 변수가 늘면 독립 변수들 사이에 존재하는 상관관계가 개입해 결과에 영향을 주는 것. PLS 회귀와 L1 정규화 등으로 해결가능.
- 다항식 회귀 : 산포도의 점 분포가 곡선 상에 위치하는 느낌을 받을 때 차수를 올려 대응하는 회귀분석 방법. 선형회귀의 한 종류.
- 과적합(Overfitting)의 문제점 : 차수를 올리면 잔차가 0에 근접할 수 있으나 이는 이미 주어진 데이터가 대상일 때 예측에 근접한 결과를 얻을 수 있고 앞으로 수집할 데이터를 대상으로 크게 벗어난 결과가 나올 가능성이 큼. 그러므로 회귀분석 할 때는 가급적 독립 변수가 낮은 차수를 갖는 모델을 설계하여 과적합을 피하는 것이 중요함.
- 최소제곱법 : 최소제곱법은 잔차 제곱의 합인 e값을 최소화하는 방법.
로지스틱 회귀¶
- 종속 변수에 약간의 수정을 가한 선형회귀. 일반화 선형 모델의 하나로 분류함.
- 로지스틱 모델의 일반식
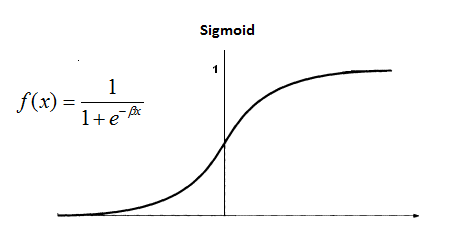
- 로짓(Logit) 변환 : 종속 변수 y에 로그를 적용해 y’로 변환하는 것.
- (http://www.saedsayad.com/images/ANN_Sigmoid.png)
03 가중 회귀분석¶
최소제곱법 수정¶
- 최소제곱법은 특잇값(Singular Value)에 취약하다는 약점 존재.
- 특잇값에 패널티를 부여하거나 제외하는 방법 등으로 수정해야 함.
LOWESS(Locally Weighted Scatterplot Smoothing) 분석¶
- 어떤 한 지점에 가중회귀 함수를 사용해 평활화(smoothing)를 실행한 회귀 식 도출 방법.
- 임의로 설정한 폭 d(x)가 있을 때, xi의 최솟값부터 차례로 값을 증가시키면서 x에 가까운 xi 값이 되도록 가중치 wi를 산출함.
- 독립 변수의 값에서 멀어져 있는 점의 기울기를 조절함으로써 특이점 때문에 받는 영향을 무시하도록 보정하는 것.
로버스트 평활화¶
- 평활화를 실행하는 과정에서 특잇값을 없앨 수 있도록 가중치 계수 w를 설정하는 방법.
- 중위 절대편차(Median Absolute Deviation, MAD)를 산출했을 때 6배 이상의 잔차 ri가 존재하면 wi를 0으로 설정함.
- 변화 상태에서 크게 벗어났다고 예상되는 점이 특이점 때문에 받는 영향을 무시하도록 보정하는 것.
L2 정규화, L1 정규화¶
- 최소제곱법으로 구성한 방정식에 panelty를 부여하는 것.
- L2 정규화
- 최소제곱법의 종속 변수인 잔차 제곱의 합에 가중치 계수인 w1 제곱의 합을 panelty로 추가한 것.
- 능형회귀(Ridge Regression)라고도 함.
- 회귀 모델로 계산함.
- L1 정규화
- 종속 변수에 wi 절댓값을 panelty로 더해줌.
- Lasso (Least Absolute Shrinkage Selection Operator)라고도 함.
- 볼록 최적화의 추정 알고리즘 사용함.
- 외부강의자료: 15쪽의 Example 을 보면 Ridge 와 Lasso 등을 왜 하는지 직관적으로 알 수 있음
- 참고자료: An Introduction to Statistical Learning 의 chap6 를 보면 좀 더 자세히 알 수 있음
04 유사도¶
유사도¶
- 변숫값 쌍이 얼마나 ‘비슷한가’ 확인하는 과정은 컴퓨터가 자동으로 답을 추측하는 과정에서 매우 중요함.
코사인 유사도¶
- 유사도 : 변숫값 x, y가 주어졌을 때 cosθ의 값.
- 범위 : 0 ~ 1 (유사도가 높을수록 1에 가까워짐)
- 문서 사이의 유사도를 계산하는데 사용됨.
- 단어목록 n : 유사도를 요구하는 문서 1과 문서 2의 모든 단어로 구성.
- x : 문서 1의 단어가 나오는 빈도 (i = 1, 2, …, n)
- y : 문서 2의 단어가 나오는 빈도 (i = 1, 2, …, n)
- 변숫값 쌍은 산포도를 사용해 점의 집합으로 나타낼 수 있으며, 점 각각은 원점으로부터의 벡터로 나타낼 수 있음.
상관계수¶
- 상관관계 : 2개의 확률 변수 사이 분포 규칙의 관계 (한 쪽이 증가하면 다른 한 쪽도 증가하고, 한 쪽이 감소하면 다른 한 쪽도 감소하는 것.)로 대부분 선형 관계의 정도를 의미함.
- 피어슨 상관계수
- r : -1(음의 상관계수) ~ 1(양의 상관계수)
- 절댓값 0.7 이상이면 상관관계가 있다고 판단.
- 스피어만의 순위 상관계수
- 피어슨 상관계수의 특별한 경우. 같은 순위가 있다면 순위를 보정해야 하지만, 적을 때는 순위 보정 필요없음.
- 켄달의 순위 상관계수
- 같은 순위인 데이터의 개수 K, 다른 순위인 데이터의 개수 L을 사용하여 계산.
- r : -1 ~ 1
상관함수¶
- 함수의 유사도를 구할 때 사용하는 방법.
- 특정 시점의 결괏값 쌍으로 상관계수를 구한 후 이를 함수로 나타낸 것.
- 교차상관함수 : 두 함수에서 어떤 시점의 두 함수 결괏값 쌍의 상관계수를 구해 함수로 나타내는 것.
- 자기상관함수 : 두 함수가 같은 함수일 때 서로 다른 시점의 함수 결괏값 상관계수를 구할 때 사용함.
- 함수의 주기성 검증
- 합성곱 처리
- 푸리에 변환 등의 신호 처리에 사용
거리와 유사도¶
- 거리가 가까울수록 유사도가 높다.
- 편집 거리(Edit Distance)
- 치환, 삽입, 삭제의 세 가지 요소에 각각 panelty를 설정하는 형태를 취하고 panelty의 합계를 점수로 설정해 유사도를 구하는 방법.
- 레벤슈타인 거리(Levenshtein Distance)
- 값이 아닌 문자열 사이의 유사도를 나타낼 때 사용하는 방법.
- 영어 단어의 검색 서비스
- 해밍 거리(Hamming Distance)
- 고정 길이의 이진 데이터에서 서로 다른 비트 부호 갖는 문자 개수.
- 2개 비트열의 배타적 논리합을 구한 결과에 존재하는 1의 개수.
- 오류 검사, 유전자를 구성하는 염기서열이나 아미노산 서열의 상동성을 계산하는데 사용
- 유클리드 거리
- 2차원 분산형 차트에서 변숫값 쌍의 관계를 표현할 때 점 2개의 좌표 사이 직선거리를 의미.
- 마할라노비스 거리 (Mahalanobis Distance)
- 유클리드 거리에서 점 수를 늘려 거리를 구하는 것.
- 데이터의 상관관계를 고려한 여러 개의 점 집단에서 어느 점까지의 거리를 계산.
- 자카드 계수
- 집합 2개의 유사도를 구할 때 집합 2개의 공통 요소 수를 전체 요소 수로 나눈 것.
05 텐서플로를 이용한 선형 회귀 예제¶
Chapter 5. 가중치와 최적화 프로그램¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
01 그래프 이론¶

무향 그래프와 유향 그래프¶
- 무향 그래프 (undirected graph): 그래프의 간선에 방향이 없는 그래프
- 유향 그래프 (directed graph): 그래프의 간선에 방향이 있는 그래프
- 유향 순회 그래프 (directed cyclic graph): 어떤 노드에서 자신으로 돌아오는 path가 있는 그래프
- 유향 비순회 그래프 (directed acyclic graph): cycle 이 없는 유향 그래프 (책의 설명이 좀 이상합니다. - 어떤 정점에서 출발한 후 해당 정점에 돌아오는 경로가 하나인 그래프)
- 간선 가중 그래프: 간선에 가중치가 있는 그래프 (aka network)
- 정점 가중 그래프: 정점에 가중치가 있는 그래프 (aka network)
그래프의 행렬 표현¶
그래프를 나타내는 방법 중에서 행렬로 나타내는 방법을 소개합니다. 이 책에서는 인접행렬(adjacency matrix) 와 근접행렬(incidence matrix) 를 설명합니다.

02 그래프 탐색과 최적화¶
탐색 트리 구축¶
출발점에서 목적지까지를 노드로 정의하고 각 노드와 에지에 이익, 비용과 같은 평가 값을 저장해두고 목적지에 도달하는 최적 경로를 찾을 수 있도록 트리를 구축하는 것을 말하고자 합니다. 가장 대표적인 것이 데이터베이스의 인덱스에 사용하는 이진 탐색 트리나 미로 찾기같은 경로 탐색을 위한 트리가 있습니다.


효율 좋은 탐색 방법¶
비용이라는 개념없이 순서만 처리하는 깊이 우선 탐색이나 너비 우선 탐색에는 한계가 있기 때문에 비용이라는 개념을 바탕으로 효율을 높여야 합니다.
비용에 따른 탐색 방법¶
A* algorithm의 wiki 를 참조해서 일단 개념을 이해 하고 책 내용을 보는 것이 좋겠다.
예를 들어 부산에서 서울로 출발할 때 동대구를 통과하느냐 경주를 통과하느냐에 따라 시간과 비용에 차이가 나는데 이런 경우 우선 비용을 정의해야 합니다. 이 책에서는 비용에 대해 다음의 세종류를 들고 있습니다.
- 초기 상태 -> 상태
 의 최적 경로 이동에 드는 비용의 총합
의 최적 경로 이동에 드는 비용의 총합 
- 상태 -> 목표하는 최적 경로 이동에 드는 비용의 총합

- 상태 를 거치는 초기 상태 -> 목표의 최적 경로 이동에 드는 비용의 총합

 를 최소화 하도록 노드 선택: 최적 탐색이라고 함 (optimal search). 탐색량이 많은 단점
를 최소화 하도록 노드 선택: 최적 탐색이라고 함 (optimal search). 탐색량이 많은 단점
 를 최소화 하도록 노드 탐색: 최선 우선 탐색 (Best-first search). 잘못 된 결과가 나올 수 있는 단점
를 최소화 하도록 노드 탐색: 최선 우선 탐색 (Best-first search). 잘못 된 결과가 나올 수 있는 단점
동적 계획법 (dynamic programming)¶
역자의 각주 wiki 동적계획법 을 참고하는 것이 이해하기가 더 쉽습니다.
동적 계획법은 모든 경로를 모두 비교하는 방법으로 복잡한 문제를 더 작은 단위의 문제로 나누어 작은 문제의 결과를 메모리를 사용하여 저장함으로써 계산량을 줄이는 기법을 말합니다. 이 책에서는 시계열 기준 상태변화의 예를 들어서 동적 프로그래밍의 효율성을 설명하고 있습니다.
시간  일 때
일 때  라는 상태 패턴이 N 개 존재하면 전체적으로
라는 상태 패턴이 N 개 존재하면 전체적으로  에서
에서  까지 가능한 전체 경로 수가
까지 가능한 전체 경로 수가  가 됩니다.
가 됩니다.

이렇게 모든 경로를 열거해 평가하게 되면 계산량이  가 되기 때문에 계산량을 줄이기 위해 문제를 잘게 나누어 각각의 세부 계산 결과를 메모리에 저장하여 최적해를 찾는 방법을 사용하는 것이 좋습니다.
가 되기 때문에 계산량을 줄이기 위해 문제를 잘게 나누어 각각의 세부 계산 결과를 메모리에 저장하여 최적해를 찾는 방법을 사용하는 것이 좋습니다.
여기서 점수 계산식은 다음과 같이 정의할 수 있습니다.
![F_t(S_t)=\max_{s_{t-1}}[F_{t-1}(s_{t-1})+h_t(s_{t-1},s_t)]](_images/math/788e035ec7c0de444217b912c49fd06183047664.png)
즉  시간에서의 최대값은
시간에서의 최대값은  시간까지의 최대값에 과 사이에서의 최대값만 고려하여 계산하면 됩니다. Bioinformatics 쪽에서는 Needleman-Wunsch algorithm 나 Smith-Waterman algorithm 이 대표적인 예가 되겠습니다.
시간까지의 최대값에 과 사이에서의 최대값만 고려하여 계산하면 됩니다. Bioinformatics 쪽에서는 Needleman-Wunsch algorithm 나 Smith-Waterman algorithm 이 대표적인 예가 되겠습니다.
03 유전 알고리즘¶
04 신경망¶
헵의 법칙과 형식 뉴런¶
생명체의 신경세포가 외부 자극을 받을 때 신호의 세기가 일정 기준을 넘으면 다음 신경 세포로 신호를 전달하는 것을 수학적 모델로 삼아서 만든 개념입니다. 이 수학 모델을 맥컬록-피츠 (McCulloch-Pitts) 모델이라고 합니다. 헵의 법칙은 시냅스의 가소성을 처음 제창한 사람의 이름인 도널드 헵의 이름을 따서 붙은 법칙으로 시냅스의 연결이 상호작용에 의해 강화되고 약해지는 것을 나타냅니다. 이를 신경망에서는 가중치가 변하는 것으로 모델링을 합니다.
신경망¶
형식 뉴런을 여러개 이어서 수학적인 신경회로를 구성한 것입니다.
활성화함수¶
형식 뉴런에서 받은 입력값을 출력할 때 일정 기준에 따라 출력값을 변화시키는 비선형 함수가 활성화 함수입니다. 이 책에서는 단위 계단 함수, 시그모이드 함수, 계단 함수,  를 소개하고 있습니다.
를 소개하고 있습니다.
퍼셉트론¶
입력 계층 (input layer), 출력 계층 (output layer) 로 구성이 되며 입력과 출력 사이에 은닉 계층 (hidden layer) 가 존재한다. 각 노드는 이 전 계층 (layer) 의 출력을 입력으로 받으며 연결된 edge 에 가중치 (weight) 가 있어 이들의 곱의 합을 바탕으로 활성화 함수에 의해 0과 1로 출력값을 결정한다. 퍼셉트론의 특징은 학습이 가능하다는 것으로 출력 계층의 결과치를 정답과 비교하여 맞고 틀린가에 따라 가중치를 갱신하며 정답을 찾아간다. XOR 문제에 대한 해답을 다층 퍼셉트론으로 풀 수 있음을 보였다.
볼츠만머신¶
퍼셉트론과는 달리 노드 사이에 피드백 메커니즘이 존재하는 신경망을 말합니다. 볼츠만머신은 호필드 네트워크 에 통계 개념을 더한 것으로 설명되나봅니다. 호필트 네트워크는 인간의 기억이라는 것을 모델링한 것이라고 합니다. 내용이 어려워서 일단 지나가겠습니다. 차후 딥러닝의 제한볼츠만머신이 나올때까지 업데이트 하겠습니다.
호필드 네트워크¶
사람의 경우 흐릿한 예사진만 보고도 친구의 얼굴을 찾아내는 것이 가능한데 이런 것을 associative memory 라고 부릅니다. 이를 신경망을 통해 구현하고자 한 것이 호필드 네트워크입니다. n 개의 노드로 구성된 네트워크는 대략 0.15n 개의 패턴을 기억할 수 있다고 알려져 있습니다. 전체적인 단계는 storing 과 classification step 으로 구성됩니다. input 이 들어오게 되면 storing 단계에서 생성된 패턴중에서 가장 유사한 패턴을 값으로 돌려주게 됩니다.
Rest1. [쉬어가기] 약인공지능의 발전과 딥러닝 알고리즘¶
이 문서는 MicroSoftWare VOL.391에 나온 약인공지능의 발전과 딥러닝 알고리듬 을 요약/정리한 것이다.
| Authors: | Woong Jeong |
|---|







04 이진 분류(Binary Classification)¶




06 딥러닝의 유형¶



{kind=link}
Chapter 6. 통계 기반 머신러닝 1 - 확률분포와 모델링¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
01 통계 모델과 확률분포¶
확률기반¶
확률분포 란 확률변수가 특정한 값을 가질 확률을 나타내는 함수를 의미합니다.
- 연속 확률분포 : 확률 밀도 함수를 이용해 표현할 수 있는 확률분포를 의미합니다. 정규분포, 연속균등분포, 카이제곱분포 등이 있습니다.
- 이산 확률분포 : 이산 확률변수가 가지는 확률분포를 의미합니다. 이산균등분포, 푸아송분포, 베르누이분포, 기하분포,초기하분포,이항분포 등이 있습니다.
머신러닝¶
머신러닝이란 “기계가 학습한다”는 개념을 의미하는 용어로, 입력 데이터의 특성과 분포, 경향 등에서 자동으로 데이터를 나누거나 재구성 하는 것을 의미합니다.
- 지도학습(Supervised Learning) : 데이터에 정답 정보가 결합된 학습 데이터(또는 훈련 데이터)로 데이터의 특징을 모델링하는 과정을 의미합니다. 주로 식별과 예측 등을 목적으로 둘 때가 많으므로 데이터를 선형 결합으로 나타내려는 특성을 이용합니다.
- 자율학습(Unsupervised Learning) : 입력 데이터의 정답을 모르는 상태에서 사용하는 것으로 클러스터 분석, 차원압축, 밀도추정 등이 해당합니다.

주요 기저함수¶
기저함수는 확률분포 모델에 따라 연속 확률분포와 이산 확률분포로 분류됩니다.
- 연속 확률분포
- 정규분포
정규분포 는 가장 많이 사용하는 분포 개념으로 가우스 분포(Gaussian distribution)라고도 합니다. 실험의 측정 오차나 사회 현상 등 자연계의 현상은 정규분포를 따르는 경향이 있습니다.


- 감마분포
감마분포 는 특정 수의 사건이 일어날 때까지 걸리는 시간에 관한 연속 확률분포 입니다. 모양 매개변수가 k이고 크기 매개변수가 θ일 때, 평균은 kθ, 분산은 kθ^2입니다. k=1 일 때 지수분포, k가 반정수((2n-1)/2)고 θ=2 일 때 카이제곱 분포라고 합니다.


- 지수분포
지수분포 는 감마분포의 모양 매개변수 k=1 일 때 사건이 일어나는 시간 간격의 확률분포를 의미합니다. 푸아송 분포와도 깊은 연관이 있습니다.


- 베타분포
베타분포 는 2개의 변수를 갖는 특수 함수인 베타함수를 이용한 분포입니다. 매개변수 a, b를 바꾸면 다양한 분포를 나타낼 수 있으므로 베이즈 통계학에서는 사전분포 모델로 이용할 때가 많습니다.


- 디리클레 분포
디리클레 분포(Dirichlet distribution) 는 베타분포를 다변량으로 확장한 것으로 다변량 베타분포라고도 합니다. 연속함수지만 2차원 평면에서는 연속함수로 나타낼 수 없습니다. 확률자체를 확률분포로 두는 분포로 자연어 처리 등에 많이 사용합니다.


- 이산 확률분포
- 이항분포
이항분포 란 베르누이 시행(두 가지 종류 중 어느 하나가 나오는가와 같은 실험)을 여러 번 시행했을 때 확률분포를 의미합니다. 정규분포나 포아송분포와 비슷합니다.


- 음이항분포
음이항분포 란 r번 성공하는데 필요한 시행횟수 k의 분포를 의미합니다. 생명과학 분야에서 많이 사용합니다.


- 푸아송분포
푸아송분포 란 일정 시간 간격에 걸쳐 평균 λ번 일어나는 현상이 k번 발생할 확률분포를 의미합니다. 지수분포가 사건이 일어난 후 다시 발생할 때까지의 시간 간격에 대한 확률밀도를 나타내는 반면, 푸아송분포는 단위 시간에 사건이 일어날 확률을 나타내므로 이 둘은 같은 사건의 발생 확률을 다른 측면에서 본다고 이해할 수 있습니다.


- 카이제곱분포
카이제곱분포 란 집단을 몇 가지로 나눴을 때 크기가 작은 집단에 보편성이 있는지 확인할 수 있는 분포입니다. 통계적 추론에서는 카이제곱 검정(독립성 검정)으로 자주 이용하며, 임상시험이나 사회과학 설문조사 등에 자주 사용합니다.


- 초기하분포
초기하분포 란 반복하지 않는 시도에서 사건이 발생할 확률분포를 의미합니다.


- 로지스틱분포
로지스틱분포 란 확률분포의 확률변수가 특정 값보다 작거나 같은 확률을 나타내는 누적분포 함수가 로지스틱 함수인 분포를 의미합니다. 정규분포와 비슷하지만 그래프의 아래가 길어 평균에서 멀어지더라도 정규분포처럼 곡선이 내려가지 않습니다.


- 확률분포 정리

손실함수와 경사 하강법¶
- 손실함수
생성된 모델을 통해 도출한 결과 값과 기대하던 값 사이 오차를 계산하는 함수입니다. 이 오차를 제곱한 값의 합계가 최솟값이 되도록 구하는 과정은 경사 하강법을 사용합니다.
- 경사 하강법(Gradient descent method)
경사 하강법 은 손실함수 위 한 점 w1에서 편미분 한 결과(기울기)가 0이 될 때까지 w의 위치에 변화를 주면서 손실 함수의 최솟값을 찾아 나가는 방법입니다. 경사 혹은 기울기는 x-y 평면에서 두 변수의 관계를 설명해 줍니다. 우리는 신경망의 오차와 각 계수의 관계에 관심이 있습니다. 즉, 각 계수의 값을 증가 혹은 감소시켰을 때 신경망의 오차가 어떻게 변화하는지 그 관계에 주목합니다. 모델의 학습은 모델의 계수를 업데이트해서 오차를 줄여나가는 과정입니다.

02 베이즈 통계학과 베이즈 추론¶
베이즈 정리¶
- 베이즈정리
베이즈정리 는 두 종류의 조건부 확률 사이의 관계를 정의합니다. 일반적인 베이즈정리 식입니다. 사후확률(Posterior probability)은 사전확률(Prior probability)과 우도(likelihood)의 곱과 같습니다.

- 베이즈정리 용어
- 사전확률 (Prior Probability)
관측자가 이미 알고있는 사건으로부터 나온 확률. P(A), P(B)
- 우도 (Likelihood Probability)
이미 알고있는 사건이 발생했다는 조건하에 다른 사건이 발생할 확률. P(B|A)
- 사후확률 (Posterior Probability)
사전확률과 우도를 통해서 알게되는 조건부 확률. P(A|B)

- 베이즈정리 예제
- 유방암 검사
A씨가 유방암 검사결과 양성으로 판정받았습니다. (유방암 검사의 정확도는 90%) 과연 A씨가 유방암에 걸린 것으로 나올 확률은 몇 %일까요?

A씨는 ‘양성반응일 때 유방암에 걸릴 확률’을 구하는 것입니다.
즉, 양성반응이라는 전제하에 유방암에 걸릴 확률 P(유방암|양성반응)은,
P(유방암|양성반응) = P(양성반응|유방암) * P(유방암) / P(양성반응)
P(양성반응|유방암) = 0.9
P(유방암) = 0.01
p(양성반응) = 유방암일 때 양성반응일 확률 + 유방암이 아닐 때 양성반응일 확률
= 0.9 * 0.01 + 0.1 * 0.99
= 0.108
따라서 P(유방암|양성반응) = 0.9 * 0.01 / 0.108 = 0.083
유방암 검사에서 양성반응일 경우 유방암일 확률은 약 8.3% 입니다.
- 몬티홀 문제

B씨가 1번 문을 선택한 경우 ‘진행자가 3번문을 열었을 때 자동차가 1번 문에 있을 확률’과 ‘진행자가 3번문을 열었을 때 자동차가 2번 문에 있을 확률’을 구하여 비교하는 것 입니다.
P(자동차1번|선택3번) = P(선택3번|자동차1번) * P(자동차1번) / P(선택3번)
P(선택3번|자동차1번) = 1/2
P(자동차1번) = 1/3
P(선택3번) = 1/2
따라서 P(자동차1번|선택3번) = (1/2 * 1/3) / 1/2 = 1/3
P(자동차2번|선택3번) = P(선택3번|자동차2번) * P(자동차1번) / P(선택2번)
P(선택3번|자동차2번) = 1
P(자동차2번) = 1/3
P(선택3번) = 1/2
따라서 P(자동차2번|선택3번) = (1 * 1/3) / 1/2 = 2/3
B씨는 선택을 바꾸는 것이 확률적으로 유리합니다.

최대가능도 방법과 EM 알고리즘¶
- 최대가능도 방법
관측데이터에서 의미있는 값을 구할 때 손실함수를 생성한 뒤 가능도함수 를 생성할 수 있습니다. 가능도함수가 최대가 되는 θ값을 정했을 때 θ는 최대가능도 추정량(Maximum Likelihood Estimation, MLE)라고 합니다. 엔트로피가 높은 상태, 즉 노이즈가 가장 균형있게 흩어져 있는 상태를 최대가능도 추정량으로 정해서 의미있는 데이터를 구할 수도 있습니다. 복잡한 가능도함수에서는 최대가능도 추정량을 직접 구할 수 없을 때가 많으며 보통 반복 계산으로 구하는 방법을 선택합니다.
- EM 알고리즘
EM 알고리즘 은 숨겨진 변수를 포함하는 모델에 사용하는 가상 데이터 전체의 가능도함수를 바탕으로 불완전한 데이터에서 최대가능도 추정량을 구하는 방법을 의미합니다. Expectation 단계와 maximization 단계로 구성됩니다.
- E (Expectation) Step
아래쪽 경계를 결정하기 위한 θ에 의존하는 볼록함수 Q를 결정하는 단계.
- M (Maximization) Step
반복실행하여 Q에서의 θ를 극대화하는 단계.
max p(X|θ) = ∑ p(X,Z|θ)
lnp(X|θ) = L(q,θ)+ KL(q∥p)
L(q,θ) = ∑ q(Z) ln(p(X,Z|θ)/q(Z)) and KL(q∥p) = −∑ q(Z)ln(p(Z|X,θ)/q(Z))
각 curve는 θ값이 고정되어 있을 때, q(Z)에 대한 lower bound L(q,θ)의 값을 의미합니다. E step을 반복할 때마다 고정된 θ에 대해 p(Z)를 풀게 되는데, 이는 곧 log-likelihood와 curve의 접점을 찾는 과정과 같습니다. 또한 M step에서는 θ값 자체를 현재값보다 더 좋은 지점으로 update시켜서 curve 자체를 이동시키는 것 입니다. 이런 과정을 반복하면 알고리즘은 언젠가 local optimum으로 수렴하게 됩니다.

베이즈 추론¶
베이즈 추론은 관측하지 않은 데이터를 다루며, 추론해야 하는 대상이 매개변수 θ일 때 확률밀도함수 Φ(θ)를 사전분포 혹은 주관분포라고 합니다. 이 식이 중요한 이유는 관측할 수 있는 데이터 이외에도 데이터에 대한 적절한 가정이 있다면 관측한 데이터만을 사용한 것보다 더 우수한 parameter estimation이 가능하기 때문입니다. 사후분포의 특징을 정하는 매개변수로는 베이즈 추정량, 사후 메디안 추정량, 최대 사후확률(MAP) 추정량의 세 가지가 있습니다.
p(Y|X) = p(X|Y)p(Y) / p(X)
- 베이즈 추정량
사후분포의 평균제곱오차를 최소화하는 값을 베이즈 추정 이라고 합니다.
- 사후 메디안 추정량
사후분포의 평균 절대 오차를 최소화하는 값으로 사후분포의 중간값입니다.
- MAP 추정량
사후밀도를 최대화하는 θ값으로 사후 최빈량 추정량이라고도 합니다.
베이즈 판별분석¶
판별분석은 데이터 x가 어떤 모집단분포에서 유래했는지 파악하는데 사용하며, 여기에 베이즈 통계학 개념이 포함된 요소를 추가한 것이 베이즈 판별분석 입니다.
N가지 종류의 데이터 x와 추론 대상 매개변수 i가 있는 모집단분포 f(x|i)와 사전분포 Φ(i)로부터 사후확률이 최대가 되는 모집단 분포의 유래를 판별합니다.
03 마르코프 연쇄 몬테카를로 방법¶
원주율의 근삿값 계산 문제¶
베이즈 추론을 실행하려고 구축한 모델은 여러 번 계산을 반복하는 것이 중요하나, ‘분포’를 구하는 현대 베이즈 추론에서는 분석할 수 없는 함수를 대상으로도 예측과 최적화 작업을 실행해야 하므로 실행횟수를 대폭 늘려줘야 합니다. 실행횟수를 늘려야 할 때는 조금씩 다른 매개변수를 무작위로 샘플링할 수 있어야합니다.
- 뷔퐁의 바늘 (L’aiguille de Buffon)
뷔퐁의 바늘 에 대한 설명은 다음 페이지 에서 쉽게 설명하고 있습니다. 또한 다음 페이지 에서 직접 시행해 볼 수 있습니다.
몬테카를로 방법¶
몬테카를로 방법은 난수를 이용하여 함수의 값을 확률적으로 계산하는 알고리즘으로 수학이나 물리학에서 자주 사용됩니다. 스타니스와프 울람이 모나코의 유명한 도박의 도시 몬테카를로의 이름을 본 따 명명했습니다.

- 마르코프 연쇄 (Markov Chain)
- Z t로부터 Z t+1로 transition 진행은 transition matrix T i,j에 의해 일어납니다.
- 즉, 한 상태 Z의 확률은 단지 그 이전 상태에만 의존한다는 것이 markov chain의 핵심입니다.
- 각 node(Z)는 각각의 probability distribution을 가지고 있습니다. (Stochastic observation의 경우 Z t의 확률형태로 표현)
- P(Z t+1)은 P(Z t)와 P(Z t+1| Z t)로 구할 수 있습니다.
- 아주 많은 chain으로 상태전이가 계속될 때 반복 계산하여 P(Z t+1)을 계산할 수 있습니다.
- Markov chain의 특수한 형태인 Stationary Distribution은 메트로폴리스-헤이스팅스 알고리즘을 작동하도록 만드는 핵심조건 입니다.
- Stationary Distribution은 π(모든 state마다 정의되는 확률분포 값. Model이 각 상태 Z에 있을 확률분포)가 t에 따라 더이상 변화하지 않는 상태입니다. (πT = π)

- Traditional Markov Chain Analysis
- Given P(Z t+1 | Z t) (=Transition Rule)…
- Find π(Z) (=Stationary distribution)
- Markov Chain Monte Carlo (MCMC)
- Given π(Z)…
- Find prescription for an efficient transition rule to reach the stationary distribution
- 즉, 어떤 목표 확률분포로부터 random sample을 얻는 방법입니다.
- How to? 우리가 알고있는 π(Z)를 잘 표현할 수 있는 transition matrix를 만들어서 sampling을 반복적으로 진행합니다.
- MaryCalls, Alarm이 Evidence node라고 가정할 때, 나머지 node들에 random 값을 assign해야합니다. 이 때 상태 Z t에서 MCMC로 계산된 transition rule을 사용하여 상태 Z t+1로 변화시켜보고 각 노드들의 assign 된 값을 확인합니다. 결국 가장 많이 나오는 값(most likely value)을 알지 못하던 latent variable에 assign 할 수 있습니다.

- Matropolis-Hastings 알고리즘
- π(Z)를 잘 표현할 수 있는 transition matrix를 만드는 핵심 알고리즘입니다.
- Current value Z t가 있을 때, candidate Z * ~ q(Z * | Z t)를 propose합니다.
- Proposal distribution으로부터 나온 random sample y의 확률과 x의 확률을 비교하여 acceptance probability(α)를 계산합니다.
- 다음 acceptance probability(α)에 따라 Z * (accept) 혹은 Z t(reject)를 취합니다.
04 은닉 마르코프 모델과 베이즈 네트워크¶
은닉 마르코프 모델¶
- 은닉 마르코프 모델 (HMM, Hidden Markov Model, Dynamic Clustering)
- Indepentent한 data(latent variables)들로부터 시간 경과에 따라 앞/뒤 상태에 영향을 주는 모델을 의미합니다. 각 상태가 markov chain을 따르되 state는 은닉되어 있다고 가정합니다. Latent random variable인 z1은 시간 t1에서 x1이 관찰됩니다. 또한 z1은 이후 latent random variable인 z2에 영향을 미칩니다. 여기에서 x1은 P(x1|z1)라는 emission probability로 표현할 수 있습니다.

- HMM의 main questions
- Evaluation question
- Given π, a(transition probability matrix), b(zi에서 ti일 때 xi가 나타날 emission probability), X…
- Find P(X|M, π, a, b) : Trained model M에서 X 가능성은 어느 정도입니까?
- 중복되는 계산 결과(전방확률)는 어딘가에 저장해 두었다가 필요할 때마다 불러서 쓴다는 것입니다. N개의 은닉상태가 있고 관측치 길이가 T라면 고려해야 할 가짓수가 N^T개나 되는데 중복되는 계산을 저장해 둔다면 계산이 훨씬 간단해 집니다.
- Decoding question
- Given π, a, b, X…
- Find argmax z P(Z|X, M, π, a, b) : 가장 가능성이 높은(최적의) Z(latent state)는 무엇입니까?
- 이미 π, a, b가 주어진 상황에서 Z를 구한다는 점에서 ‘supervisez learning’과 유사합니다.
- 모델의 최적(최대확률을 가진) 상태를 구하는 Viterbi 알고리즘이 있습니다. Evaluation question과 가장 큰 차이점은 역추적(backtracking) 과정이 존재한다는 점입니다.
- 나열된 단어에서 품사 태그를 찾는 것 등에 사용할 수 있습니다.
- Learning question
- Given X…
- Find argmax π,a,b P(X|M, π, a, b) : X(observation)만 주어진 상황에서 HMM의 underlying parameters(π, a, b)는 무엇이 있습니까?
- π, a, b가 알려지지 않은 상황에서 이를 추정한다는 점에서 ‘unsupervised learning’과 유사합니다.
- Baum-Welch 알고리즘(EM algorithm for HMM, Forward-Backward algorithm)이 있습니다.
- Optimized π, a, b (예측값)을 구합니다. 이 때 EM 알고리즘(Expectation-Maximization)을 사용합니다.
- X, Optimized π, a, b로부터 가장 가능성이 높은(최적의) Z를 구합니다. (Decoding)
베이즈 네트워크¶
베이즈 네트워크 는 acyclic and directed graph와 a set of nodes, a set of link를 통해 random variable을 conditionally independent하게 표현하는 graphical notation입니다.

- Typical Local Structure
- Common Parent
- J ⊥ M|A
- P(J,M|A) = P(J|A)P(M|A)
- Cascading
- B ⊥ M|A
- P(M|B,A) = P(M|A)
- V-Structure
- ~(B ⊥ M|A)
- P(B,E,A) = P(B)P(E)P(A|B,E)
Chapter 7. 통계 기반 머신러닝 2 - 자율 학습과 지도 학습¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
| Authors: | Woong Jeong |
|---|
01 자율 학습¶
자율 학습¶
클러스터 분석과 K-평균 알고리즘¶

주성분 분석¶
특이값 분해¶
독립 성분 분석¶
자기조직화지도¶
Chapter 9. 딥러닝¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
Chapter 10. 이미지와 음성 패턴 인식¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
Chapter 11. 자연어 처리와 머신러닝¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
Chapter 12. 지식 표현과 데이터 구조¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
Chapter 13. 분산 컴퓨팅¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
Chapter 14. 빅데이터와 사물인터넷의 관계¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.