Introduction to CREDO¶
CREDO is a Python toolkit for system testing, benchmarking and analysis of Modelling tools based on the StGermain framework, such as Underworld.
It is distributed with the stgUnderworld application bundle, but in future it’s planned that it will also be possible to be obtained and installed independently.
Core design goals¶
CREDO’s core design goals are to:
- Support the effective development, inquiry and maintenance of a suite of benchmarks that test the scientific features, numerical accuracy, and computational performance of StGermain-based codes.
- Significantly enhance the ease and effectiveness of performing scientific analysis of the results of StGermain modelling applications.
Both these tasks are possible using a combination of command lines and custom 3rd party tools, both proprietary and open source - but the goal of CREDO is to provide an integrated system that makes doing both of them to a high level much easier and clearer - and also in a readily repeatable manner so that the status of a code as it evolves can be readily checked (e.g. as part of a continuous integration system).
To meet these goals, we chose the Python scripting and programming language, explained more in the Language choice - why Python? section below.
How CREDO fits into the workflow of using the Underworld modelling code¶
CREDO still runs StGermain codes such as Underworld “under the hood”, but it’s role is to:
- Construct XML data files based on the analysis/testing the user asks for in a CREDO script;
- Launch the necessary StGermain jobs required to perform the analysis;
- ..and finally provide access to the results created by the model at a high-level, facilitate post-processing of these results, and perform any post-run analysis required by tests/benchmarks.
This is summarised in the diagram below.
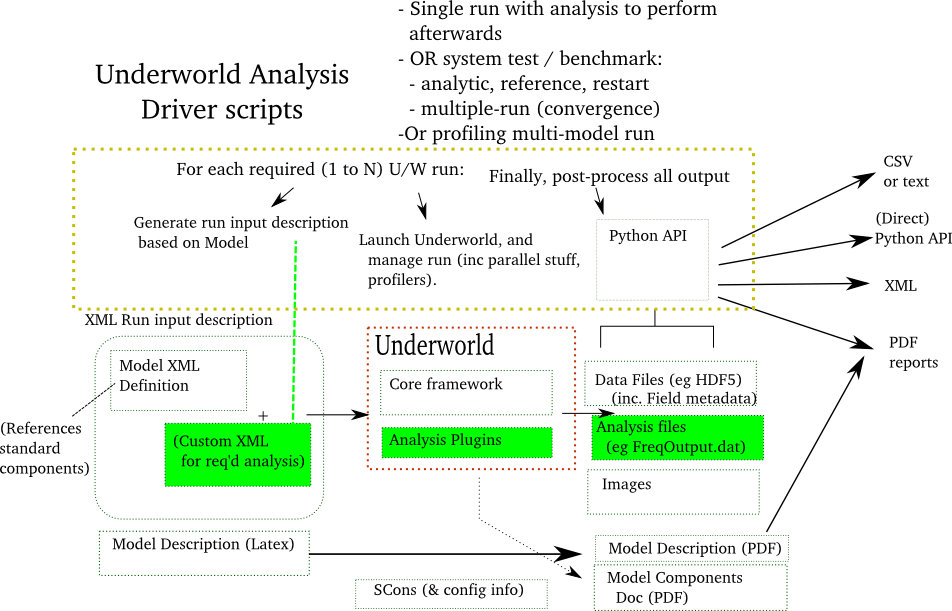
As such, it currently explicity doesn’t provide run-time access to the StGermain objects (written in a custom framework implemented in the C language). Rather, it works in detail with the StGermain XML format for defining models, and the defined StGermain data output formats.
CREDO’s Benchmarking Goals / Motivation¶
There has long been an interest in a more systematic way of testing both the software performance, and scientific/numerical reliability of the StgUnderworld code – for example the issue was explored in a paper presented at the APAC05 conference [FarringtonEtAl2005].
The benefits of such a system are:
- A clear and up-to-date record of the performance and reliability of the code to present to scientists interested in using it or comparing it to similar codes. The chosen benchmarks would be of a “scope” of much more interest to modellers and scientists than the detailed unit and integration tests. This ties in to the concept of ‘reproducible research’ ([FomelHennenfent2007]).
- A definitive record to examine the changing performance of the code over time, which has always been a big concern among the existing research community using the code;
- As a corollary to the above, the system would give the development team a clear and timely warning if a design change accidentally negatively affected performance or accuracy – which has been a problem in the past.
- The ability to use the science benchmark suite and framework to quickly evaluate the performance of Stg-Underworld on new hardware systems, to assist purchasing decisions and new collaborators.
- The goal would be to automate as much as possible the regular collection of these benchmarks (initally proposed as weekly), assessment of them, and publishing of them on-line in a succinct and meaningful form (IE with key metrics emphasised, and linked to clear definitions of the benchmark problem).
Scientific analysis of computational codes - core capabilities¶
To achieve the above goals, the features below are either provided by CREDO, or under active development:
- Ability to quickly extract and compare observables that are produced during runs of the code (such as VRMS). This includes testing that an observable is within a given range at a given time.
- Ability to extract information about the 2D or 3D mesh, field
or swarm data produced by a StGermain application.
- For testing purposes, this includes functions like checking that a field produced by the model run compares as expected with a reference field, loaded in from a separate data file.
- Ability to record, and compare performance metadata about the code, such as time that simulations ran for, memory usage, etc.
Examples of doing this sort of analysis and testing is provided in the Examples of how to use CREDO section.
Language choice - why Python?¶
The CREDO code is written in the dynamic scripting and programming language Python. Python was chosen as the implementation language because of:
- It’s ability to run in either interactive or scripted mode:- and thus facilitate either scripted, repeatable workflows, or interactive exploration;
- The fact that it’s clear, concise syntax and high level of abstraction is recommended for human developer productivity - while computationally intensive tasks can be performed in compiled languages and libraries (such as Underworld itself).
- The fact that it’s a highly portable language between operating systems and architectures.
- The increasingly stable, feature-rich and wide-ranging set of open source packages for mathematical and scientific analysis in Python, such as SciPy, NumPy, Matplotlib, SAGE, Paraview, and MayaVI.
The fact that CREDO is written in Python doesn’t prevent you from using a favourite tool or language for your final analysis work - in this case, CREDO is being written to allow you to extract the needed observables from a set of model results in common formats such as CSV or XML files.
Footnotes
| [FarringtonEtAl2005] | Farrington, R, Moresi, L, Quenette, S, Turnbull, R, & Sunter, P, 2005, ‘Geodynamic benchmarking tests in HPC’, Presented at the 2005 APAC Conference, Gold Coast, Australia. |
| [FomelHennenfent2007] | S. Fomel and G. Hennenfent, 2007, ‘Reproducible computational experiments using SCons,’ in Proc. IEEE Int. Conf. on Acoustics, Speech and Signal Processing, vol. 4, Apr. 2007, pp. 1257–1260. [Online]. Available: http://slim.eos.ubc.ca/Publications/Public/Conferences/ICASSP/2007/fomel07icassp.pdf |